!pip install lancedb sentence-transformers cohere tantivy pyarrow==13.0.0 -q
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 177.4/177.4 kB 4.7 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 139.2/139.2 kB 6.2 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.1/3.1 MB 16.4 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 75.6/75.6 kB 10.2 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.4/12.4 MB 51.0 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 82.7/82.7 kB 12.2 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.9/77.9 kB 11.8 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.3/58.3 kB 7.6 MB/s eta 0:00:00
What is a retriever¶
VectorDBs are used as retrievers in recommender or chatbot-based systems for retrieving relevant data based on user queries. For example, retriever is a critical component of Retrieval Augmented Generation (RAG) acrhitectures. In this section, we will discuss how to improve the performance of retrievers.
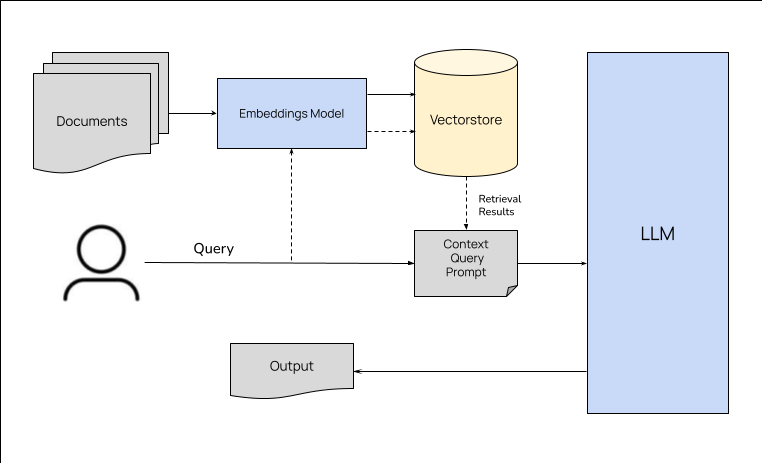
How do you go about improving retreival performance¶
Some of the common techniques are:
- Using different search types - vector/semantic, FTS (BM25)
- Hybrid search
- Reranking
- Fine-tuning the embedding models
- Using different embedding models
Obviously, the above list is not exhaustive. There are other subtler ways that can improve retrieval performance like alternative chunking algorithms, using different distance/similarity metrics, and more. For brevity, we'll only cover high level and more impactful techniques here.
LanceDB¶
- Multimodal DB for AI
- Powered by an innovative & open-source in-house file format
- Zero setup
- Scales up on disk storage
- Native support for vector, full-text(BM25) and hybrid search
The dataset¶
The dataset we'll use is a synthetic QA dataset generated from LLama2 review paper. The paper was divided into chunks, with each chunk being a unique context. An LLM was prompted to ask questions relevant to the context for testing a retriever. The exact code and other utility functions for this can be found in this repo.
!wget https://raw.githubusercontent.com/AyushExel/assets/main/data_qa.csv
--2024-07-24 14:22:47-- https://raw.githubusercontent.com/AyushExel/assets/main/data_qa.csv Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 680439 (664K) [text/plain] Saving to: ‘data_qa.csv’ data_qa.csv 100%[===================>] 664.49K --.-KB/s in 0.03s 2024-07-24 14:22:48 (19.9 MB/s) - ‘data_qa.csv’ saved [680439/680439]
import pandas as pd
data = pd.read_csv("data_qa.csv")
data
| Unnamed: 0 | query | context | answer | |
|---|---|---|---|---|
| 0 | 0 | How does the performance of Llama 2-Chat model... | Llama 2 : Open Foundation and Fine-Tuned Chat ... | Llama 2-Chat models have shown to exceed the p... |
| 1 | 1 | What benefits does the enhancement and safety ... | Llama 2 : Open Foundation and Fine-Tuned Chat ... | The safety and enhancement measures implemente... |
| 2 | 2 | How does one ensure the reliability and robust... | Contents\n1 Introduction 3\n2 Pretraining 5\n2... | In the initial steps of model development, the... |
| 3 | 3 | What methodologies are employed to align machi... | Contents\n1 Introduction 3\n2 Pretraining 5\n2... | Machine learning models can be aligned with de... |
| 4 | 4 | What are some of the primary insights gained f... | . . . . . . . . 23\n4.3 Red Teaming . . . . . ... | The key insights gained from evaluating platfo... |
| ... | ... | ... | ... | ... |
| 215 | 215 | How are the terms 'clean', 'not clean', 'dirty... | Giventhe\nembarrassinglyparallelnatureofthetas... | In the discussed dataset analysis, samples are... |
| 216 | 216 | How does the size of the model influence the a... | Dataset Model Subset Type Avg. Contam. % n ¯X ... | The size of the model significantly influences... |
| 217 | 217 | What impact does the model contamination have ... | Dataset Model Subset Type Avg. Contam. % n ¯X ... | Model contamination affects various contaminat... |
| 218 | 218 | What are the different sizes and types availab... | A.7 Model Card\nTable 52 presents a model card... | Llama 2 is available in three distinct paramet... |
| 219 | 219 | Could you discuss the sustainability measures ... | A.7 Model Card\nTable 52 presents a model card... | Throughout the training of Llama 2, which invo... |
220 rows × 4 columns
Ingestion¶
Let us now ingest the contexts in LanceDB. The steps will be:
- Create a schema (Pydantic or Pyarrow)
- Select an embedding model from LanceDB Embedding API (to allow automatic vectorization of data)
- Ingest the contexts
# Define schema using Pydantic. We're using Embedding API to automatically vectorize dataset and queries
import torch
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
embed_model = get_registry().get("huggingface").create(name="BAAI/bge-small-en-v1.5", device=device)
class Schema(LanceModel):
text: str = embed_model.SourceField()
vector: Vector(embed_model.ndims()) = embed_model.VectorField()
/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_token.py:89: UserWarning: The secret `HF_TOKEN` does not exist in your Colab secrets. To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session. You will be able to reuse this secret in all of your notebooks. Please note that authentication is recommended but still optional to access public models or datasets. warnings.warn(
tokenizer_config.json: 0%| | 0.00/366 [00:00<?, ?B/s]
vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/711k [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/125 [00:00<?, ?B/s]
config.json: 0%| | 0.00/743 [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/133M [00:00<?, ?B/s]
# Create a local lancedb connection
import lancedb
db = lancedb.connect("~/lancedb/")
tbl = db.create_table("qa_data", schema=Schema, mode="overwrite")
contexts = [
{"text": context} for context in data["context"].unique()
]
print(contexts[0:5])
tbl.add(contexts)
[{'text': 'Llama 2 : Open Foundation and Fine-Tuned Chat Models\nHugo Touvron∗Louis Martin†Kevin Stone†\nPeter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra\nPrajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen\nGuillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller\nCynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou\nHakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev\nPunit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich\nYinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra\nIgor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi\nAlan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang\nRoss Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang\nAngela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic\nSergey Edunov Thomas Scialom∗\nGenAI, Meta\nAbstract\nIn this work, we develop and release Llama 2, a collection of pretrained and fine-tuned\nlarge language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.\nOur fine-tuned LLMs, called Llama 2-Chat , are optimized for dialogue use cases. Our\nmodels outperform open-source chat models on most benchmarks we tested, and based on\nourhumanevaluationsforhelpfulnessandsafety,maybeasuitablesubstituteforclosed-\nsource models. We provide a detailed description of our approach to fine-tuning and safety\nimprovements of Llama 2-Chat in order to enable the community to build on our work and\ncontribute to the responsible development of LLMs.\n∗Equal contribution, corresponding authors: {tscialom, htouvron}@meta.com\n†Second author\nContributions for all the authors can be found in Section A.1.arXiv:2307.09288v2 [cs.CL] 19 Jul 2023'}, {'text': 'Contents\n1 Introduction 3\n2 Pretraining 5\n2.1 Pretraining Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5\n2.2 Training Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5\n2.3 Llama 2 Pretrained Model Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7\n3 Fine-tuning 8\n3.1 Supervised Fine-Tuning (SFT) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9\n3.2 Reinforcement Learning with Human Feedback (RLHF) . . . . . . . . . . . . . . . . . . . . . 9\n3.3 System Message for Multi-Turn Consistency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16\n3.4 RLHF Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17\n4 Safety 20\n4.1 Safety in Pretraining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20\n4.2 Safety Fine-Tuning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23\n4.3 Red Teaming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28\n4.4 Safety Evaluation of Llama 2-Chat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .'}, {'text': '. . . . . . . . 23\n4.3 Red Teaming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28\n4.4 Safety Evaluation of Llama 2-Chat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29\n5 Discussion 32\n5.1 Learnings and Observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32\n5.2 Limitations and Ethical Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34\n5.3 Responsible Release Strategy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35\n6 Related Work 35\n7 Conclusion 36\nA Appendix 46\nA.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46\nA.2 Additional Details for Pretraining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47\nA.3 Additional Details for Fine-tuning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51\nA.4 Additional Details for Safety . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58\nA.5 Data Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72\nA.6 Dataset Contamination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .'}, {'text': '. . . . . . 58\nA.5 Data Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72\nA.6 Dataset Contamination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75\nA.7 Model Card . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77\n2'}, {'text': 'Figure 1: Helpfulness human evaluation results for Llama\n2-Chatcomparedtootheropen-sourceandclosed-source\nmodels. Human raters compared model generations on ~4k\npromptsconsistingofbothsingleandmulti-turnprompts.\nThe95%confidenceintervalsforthisevaluationarebetween\n1%and2%. MoredetailsinSection3.4.2. Whilereviewing\nthese results, it is important to note that human evaluations\ncanbenoisyduetolimitationsofthepromptset,subjectivity\nof the review guidelines, subjectivity of individual raters,\nand the inherent difficulty of comparing generations.\nFigure 2: Win-rate % for helpfulness and\nsafety between commercial-licensed base-\nlines and Llama 2-Chat , according to GPT-\n4. Tocomplementthehumanevaluation,we\nused a more capable model, not subject to\nourownguidance. Greenareaindicatesour\nmodelisbetteraccordingtoGPT-4. Toremove\nties, we used win/ (win+loss). The orders in\nwhichthemodelresponsesarepresentedto\nGPT-4arerandomlyswappedtoalleviatebias.\n1 Introduction\nLarge Language Models (LLMs) have shown great promise as highly capable AI assistants that excel in\ncomplex reasoning tasks requiring expert knowledge across a wide range of fields, including in specialized\ndomains such as programming and creative writing. They enable interaction with humans through intuitive\nchat interfaces, which has led to rapid and widespread adoption among the general public.\nThecapabilitiesofLLMsareremarkableconsideringtheseeminglystraightforwardnatureofthetraining\nmethodology. Auto-regressivetransformersarepretrainedonanextensivecorpusofself-superviseddata,\nfollowed by alignment with human preferences via techniques such as Reinforcement Learning with Human\nFeedback(RLHF).Althoughthetrainingmethodologyissimple,highcomputationalrequirementshave\nlimited the development of LLMs to a few players. There have been public releases of pretrained LLMs\n(such as BLOOM (Scao et al., 2022), LLaMa-1 (Touvron et al., 2023), and Falcon (Penedo et al., 2023)) that\nmatch the performance of closed pretrained competitors like GPT-3 (Brown et al., 2020) and Chinchilla\n(Hoffmann et al., 2022), but none of these models are suitable substitutes for closed “product” LLMs, such\nasChatGPT,BARD,andClaude. TheseclosedproductLLMsareheavilyfine-tunedtoalignwithhuman\npreferences, which greatly enhances their usability and safety. This step can require significant costs in\ncomputeandhumanannotation,andisoftennottransparentoreasilyreproducible,limitingprogresswithin\nthe community to advance AI alignment research.\nIn this work, we develop and release Llama 2, a family of pretrained and fine-tuned LLMs, Llama 2 and\nLlama 2-Chat , at scales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested,\nLlama 2-Chat models generally perform better than existing open-source models. They also appear to\nbe on par with some of the closed-source models, at least on the human evaluations we performed (see\nFigures1and3). Wehavetakenmeasurestoincreasethesafetyofthesemodels,usingsafety-specificdata\nannotation and tuning, as well as conducting red-teaming and employing iterative evaluations. Additionally,\nthispapercontributesathoroughdescriptionofourfine-tuningmethodologyandapproachtoimproving\nLLM safety. We hope that this openness will enable the community to reproduce fine-tuned LLMs and\ncontinue to improve the safety of those models, paving the way for more responsible development of LLMs.\nWealsosharenovelobservationswemadeduringthedevelopmentof Llama 2 andLlama 2-Chat ,suchas\nthe emergence of tool usage and temporal organization of knowledge.\n3'}]
Different Query types in LanceDB¶
LanceDB allows switching query types with by setting query_type argument, which defaults to vector when using Embedding API. In this example we'll use JinaReranker which is one of many rerankers supported by LanceDB.
Vector search:¶
Vector search
table.search(query, query_type="vector")` or `table.search(query)
Vector search with Reranking
reranker = JinaReranker()
table.search(query).rerank(reranker=reranker)
Full-text search:¶
FTS
table.search(query, query_type="fts")
FTS with Reranking¶
table.search(query, query_type="fts").rerank(reranker=reranker)
Hybrid search¶
table.search(query, query_type="hybrid").rerank(reranker=reranker)
"""
Util for searching lancedb table with different query types and rerankers. In case of Vector and FTS only reranking, we'll overfetch the results
by a factor of 2 and get top K after reranking. Without overfetching, vector only and fts only search results won't have any effect on hit-rate metric
"""
from lancedb.rerankers import Reranker
VALID_QUERY_TYPES = ["vector", "fts", "hybrid", "rerank_vector", "rerank_fts"]
def search_table(table: lancedb.table, reranker:Reranker, query_type: str, query_string: str, top_k:int=5, overfetch_factor:int=2):
if query_type not in VALID_QUERY_TYPES:
raise ValueError(f"Invalid query type: {query_type}")
if query_type in ["hybrid", "rerank_vector", "rerank_fts"] and reranker is None:
raise ValueError(f"Reranker must be provided for query type: {query_type}")
if query_type in ["vector", "fts"]:
rs = table.search(query_string, query_type=query_type).limit(top_k).to_pandas()
elif query_type == ["rerank_vector", "rerank_fts"]:
rs = table.search(query_string, query_type=query_type).rerank(reranker=reranker).limit(overfetch_factor*top_k).to_pandas()
elif query_type == "hybrid":
rs = table.search(query_string, query_type=query_type).rerank(reranker=reranker).limit(top_k).to_pandas()
return rs
Hit-rate eval metric¶
We'll be using a simple metric called "hit-rate" for evaluating the performance of the retriever across this guide.
Hit-rate is the percentage of queries for which the retriever returned the correct answer in the top-k results.
For example, if the retriever returned the correct answer in the top-3 results for 70% of the queries, then the hit-rate@3 is 0.7.
import tqdm
def hit_rate(ds, table, query_type:str, top_k:int = 5, reranker:Reranker = None) -> float:
eval_results = []
for idx in tqdm.tqdm(range(len(ds))):
query = ds["query"][idx]
reference_context = ds["context"][idx]
if not reference_context:
print("reference_context is None for query: {idx}. \
Skipping this query. Please check your dataset.")
continue
try:
rs = search_table(table, reranker, query_type, query, top_k)
except Exception as e:
print(f'Error with query: {idx} {e}')
eval_results.append({
'is_hit': False,
'retrieved': [],
'expected': reference_context,
'query': query,
})
continue
retrieved_texts = rs['text'].tolist()[:top_k]
expected_text = reference_context[0] if isinstance(reference_context, list) else reference_context
is_hit = False
# HACK: to handle new line characters added my llamaindex doc reader
if expected_text in retrieved_texts or expected_text+'\n' in retrieved_texts:
is_hit = True
eval_result = {
'is_hit': is_hit,
'retrieved': retrieved_texts,
'expected': expected_text,
'query': query,
}
eval_results.append(eval_result)
result = pd.DataFrame(eval_results)
hit_rate = result['is_hit'].mean()
return hit_rate
tbl.create_fts_index("text", replace=True)
hit_rate_vector = hit_rate(data, tbl, "vector")
hit_rate_fts = hit_rate(data, tbl, "fts")
print(f"\n Vector Search Hit Rate: {hit_rate_vector}")
print(f"FTS Search Hit Rate: {hit_rate_fts}")
100%|██████████| 220/220 [00:10<00:00, 21.62it/s] 100%|██████████| 220/220 [00:00<00:00, 358.03it/s]
Vector Search Hit Rate: 0.6409090909090909 FTS Search Hit Rate: 0.5954545454545455
- Reranked vector search
Hybrid Search¶
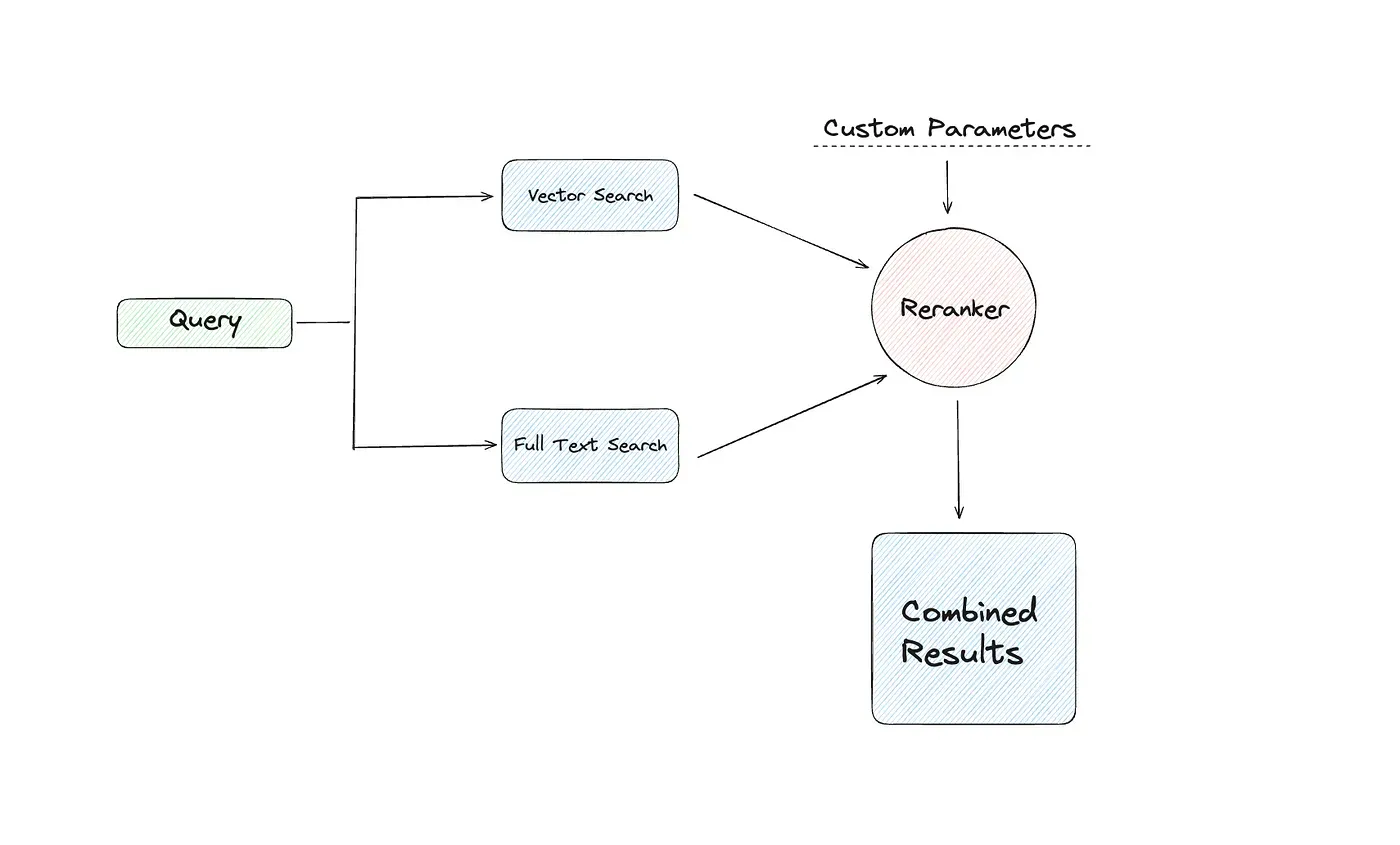
from lancedb.rerankers import LinearCombinationReranker # LanceDB hybrid search uses LinearCombinationReranker by default
reranker = LinearCombinationReranker(weight=0.7)
hit_rate_hybrid = hit_rate(data, tbl, "hybrid", reranker=reranker)
print(f"\n Hybrid Search with LinearCombinationReranker Hit Rate: {hit_rate_hybrid}")
100%|██████████| 220/220 [00:10<00:00, 20.60it/s]
Hybrid Search with LinearCombinationReranker Hit Rate: 0.6454545454545455
Trying out different rerankers¶
1. Cross Encoder Reranker¶
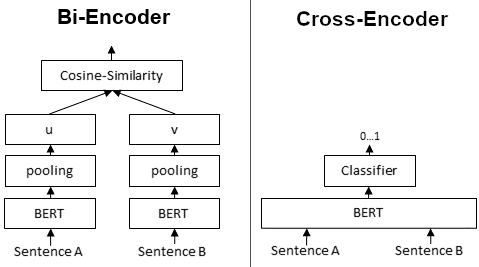
Bi-Encoders produce for a given sentence a sentence embedding. We pass to a BERT independently the sentences A and B, which result in the sentence embeddings u and v. These sentence embedding can then be compared using cosine similarity.
In contrast, for a Cross-Encoder, we pass both sentences simultaneously to the Transformer network. It produces then an output value between 0 and 1 indicating the similarity of the input sentence pair:
A Cross-Encoder does not produce a sentence embedding. Also, we are not able to pass individual sentences to a Cross-Encoder.
#WARNING: This cell takes a long time without CUDA
from lancedb.rerankers import JinaReranker, CrossEncoderReranker, CohereReranker
reranker = CrossEncoderReranker()
hit_rate_hybrid = hit_rate(data, tbl, "hybrid", reranker=reranker)
print(f" \n Hybrid Search with CrossEncoderReranker Hit Rate: {hit_rate_hybrid}")
0%| | 0/220 [00:00<?, ?it/s]
config.json: 0%| | 0.00/612 [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/268M [00:00<?, ?B/s]
tokenizer_config.json: 0%| | 0.00/541 [00:00<?, ?B/s]
vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/112 [00:00<?, ?B/s]
100%|██████████| 220/220 [01:03<00:00, 3.44it/s]
Hybrid Search with CrossEncoderReranker Hit Rate: 0.6772727272727272
- Jina AI Reranker
# Jina AI Reranker
import os
from lancedb.rerankers import JinaReranker
# Colab secret setup
from google.colab import userdata
os.environ["JINA_API_KEY"] = userdata.get('JINA_API_KEY')
reranker = JinaReranker(model_name="jina-reranker-v2-base-multilingual")
hit_rate_hybrid = hit_rate(data, tbl, "hybrid", reranker=reranker)
print(f" \n Hybrid Search with JinaReranker Hit Rate: {hit_rate_hybrid}")
100%|██████████| 220/220 [01:24<00:00, 2.60it/s]
Hybrid Search with JinaReranker Hit Rate: 0.7681818181818182
os.environ["COHERE_API_KEY"] = userdata.get('COHERE_API_KEY')
reranker = CohereReranker()
hit_rate_hybrid = hit_rate(data, tbl, "hybrid", reranker=reranker)
print(f" \n Hybrid Search with CohereReranker Hit Rate: {hit_rate_hybrid}")
All results:¶
| Query Type | Hit-rate@5 |
|---|---|
| Vector | 0.640 |
| FTS | 0.595 |
| Reranked vector (Cohere Reranker) | 0.677 |
| Reranked fts (Cohere Reranker) | 0.672 |
| Hybrid (Cohere Reranker) | 0.759 |
| Hybrid (Jina Reranker) | 0.768 |
Implementing Custom Rerankers with LanceDB¶
LanceDB
from lancedb.rerankers import Reranker
import pyarrow as pa
class MyReranker(Reranker):
def __init__(self, param1, param2, ..., return_score="relevance"):
def rerank_hybrid(self, query: str, vector_results: pa.Table, fts_results: pa.Table):
# Use the built-in merging function
combined_result = self.merge_results(vector_results, fts_results)
# Do something with the combined results
return combined_result
def rerank_vector(self, query: str, vector_results: pa.Table):
# Do something with the vector results
return vector_results
def rerank_fts(self, query: str, fts_results: pa.Table):
# Do something with the FTS results
return fts_results
Takeaways & Tradeoffs¶
Rerankers significantly improve accuracy at little cost. Using Hybrid search and/or rerankers can significantly improve retrieval performance without spending any additional time or effort on tuning embedding models, generators, or dissecting the dataset.
Reranking is an expensive operation. Depending on the type of reranker you choose, they can incur significant latecy to query times. Although some API-based rerankers can be significantly faster.
Pre-warmed GPU environments reduce latency. When using models locally, having a warmed-up GPU environment will significantly reduce latency. This is especially useful if the application doesn't need to be strictly realtime. Pre-warming comes at the expense of GPU resources.
Applications¶
Not all recommendation problems are strictly real-time. When considering problem statements involving chatbots, search recommendations, auto-complete etc. low latency is a hard requirement.
But there another category of applications where retrieval accurate information need not be real-time. For example:
Personalized music or movie recommendation: These systems generally start off by recommending close to random / or some generally accurate recommendations. They keep improving recommendations async with the user interation data.
Social media personalised timeline
Recommend blogs, videos, etc. via push notifications
"YouTube now gives notifications for "recommended", non-subscribed channels" - https://www.reddit.com/r/assholedesign/comments/807zpe/youtube_now_gives_notifications_for_recommended/
