Agentic RAG 🤖
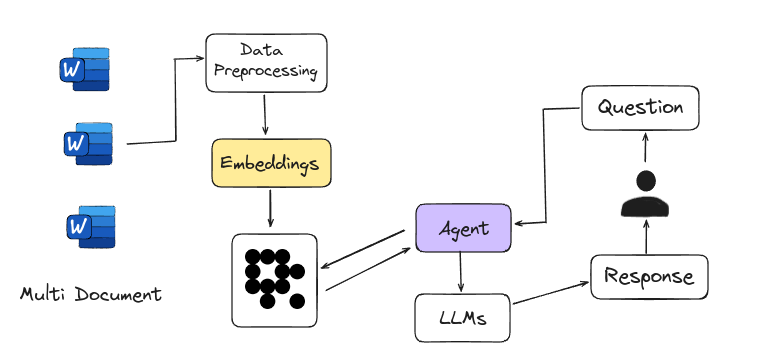
Agentic RAG introduces an advanced framework for answering questions by using intelligent agents instead of just relying on large language models. These agents act like expert researchers, handling complex tasks such as detailed planning, multi-step reasoning, and using external tools. They navigate multiple documents, compare information, and generate accurate answers. This system is easily scalable, with each new document set managed by a sub-agent, making it a powerful tool for tackling a wide range of information needs.

Here’s a code snippet for defining retriever using Langchain:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import LanceDB
from langchain_openai import OpenAIEmbeddings
urls = [
"https://content.dgft.gov.in/Website/CIEP.pdf",
"https://content.dgft.gov.in/Website/GAE.pdf",
"https://content.dgft.gov.in/Website/HTE.pdf",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
# add documents in LanceDB
vectorstore = LanceDB.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
Here is an agent that formulates an improved query for better retrieval results and then grades the retrieved documents:
def grade_documents(state) -> Literal["generate", "rewrite"]:
class grade(BaseModel):
binary_score: str = Field(description="Relevance score 'yes' or 'no'")
model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True)
llm_with_tool = model.with_structured_output(grade)
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
chain = prompt | llm_with_tool
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
return "generate" if score == "yes" else "rewrite"
def agent(state):
messages = state["messages"]
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4-turbo")
model = model.bind_tools(tools)
response = model.invoke(messages)
return {"messages": [response]}
def rewrite(state):
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f""" \n
Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """,
)
]
model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True)
response = model.invoke(msg)
return {"messages": [response]}