FiftyOne
FiftyOne is an open source toolkit for building high-quality datasets and computer vision models. It provides an API to create LanceDB tables and run similarity queries, both programmatically in Python and via point-and-click in the App.
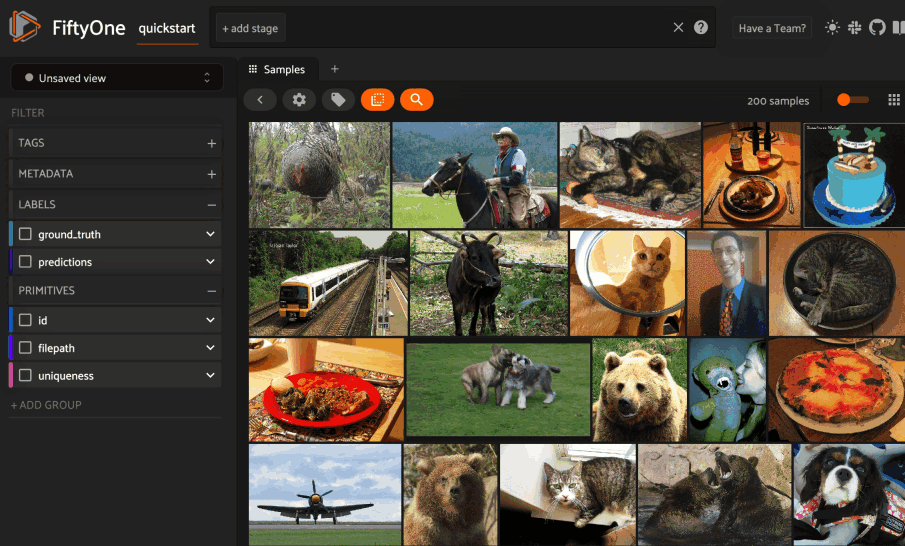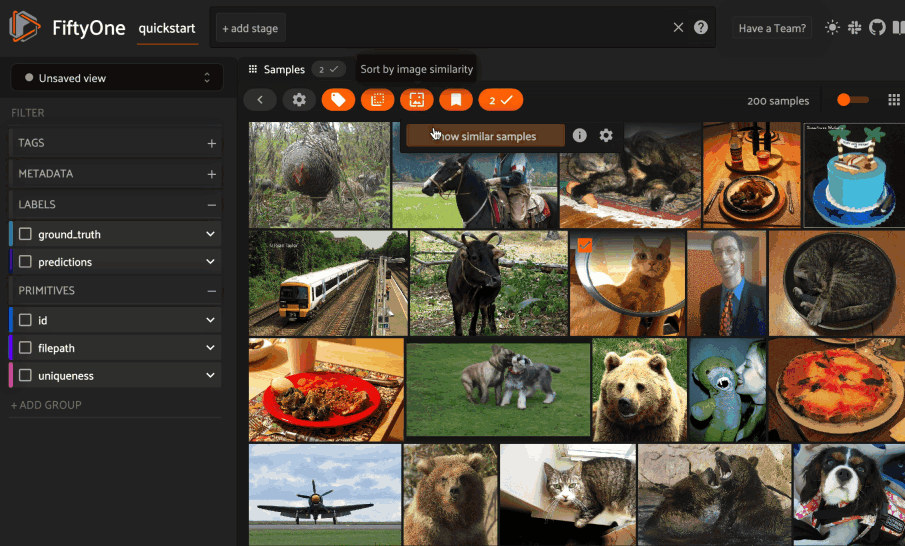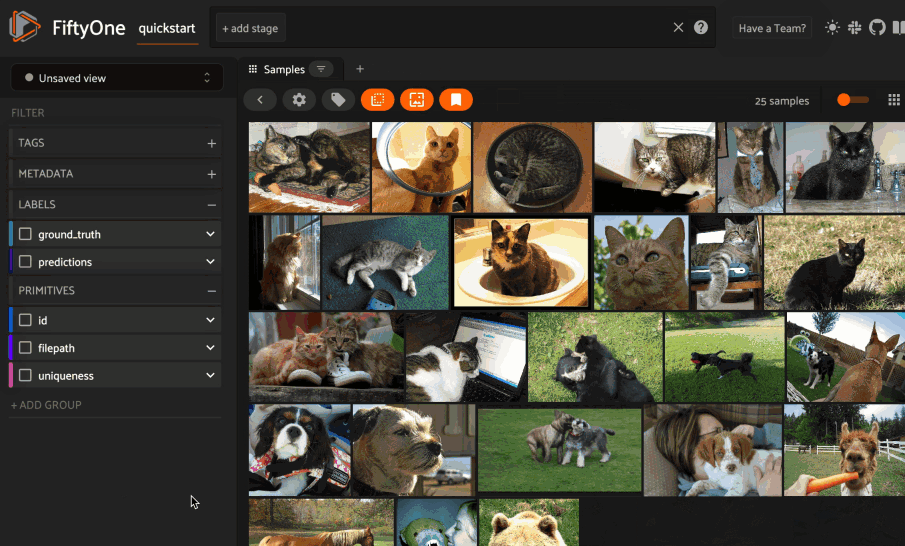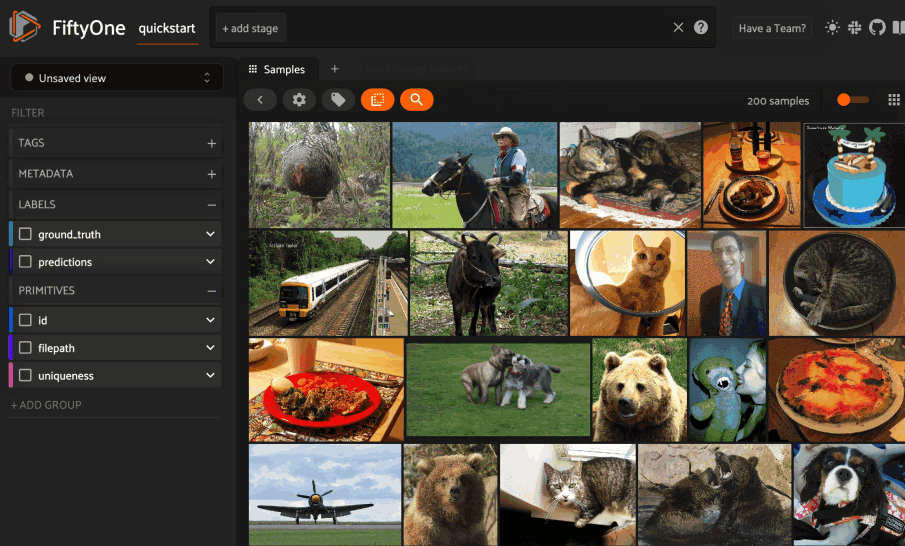
Basic recipe
The basic workflow shown below uses LanceDB to create a similarity index on your FiftyOne datasets:
-
Load a dataset into FiftyOne.
-
Compute embedding vectors for samples or patches in your dataset, or select a model to use to generate embeddings.
-
Use the
compute_similarity()method to generate a LanceDB table for the samples or object patches embeddings in a dataset by setting the parameterbackend="lancedb"and specifying abrain_keyof your choice. -
Use this LanceDB table to query your data with
sort_by_similarity(). -
If desired, delete the table.
The example below demonstrates this workflow.
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# Step 1: Load your data into FiftyOne
dataset = foz.load_zoo_dataset("quickstart")
# Steps 2 and 3: Compute embeddings and create a similarity index
lancedb_index = fob.compute_similarity(
dataset,
model="clip-vit-base32-torch",
brain_key="lancedb_index",
backend="lancedb",
)
brain_key:
# Step 4: Query your data
query = dataset.first().id # query by sample ID
view = dataset.sort_by_similarity(
query,
brain_key="lancedb_index",
k=10, # limit to 10 most similar samples
)
# Step 5 (optional): Cleanup
# Delete the LanceDB table
lancedb_index.cleanup()
# Delete run record from FiftyOne
dataset.delete_brain_run("lancedb_index")
For a much more in depth walkthrough of the integration, visit the LanceDB x Voxel51 docs page.