Quick start
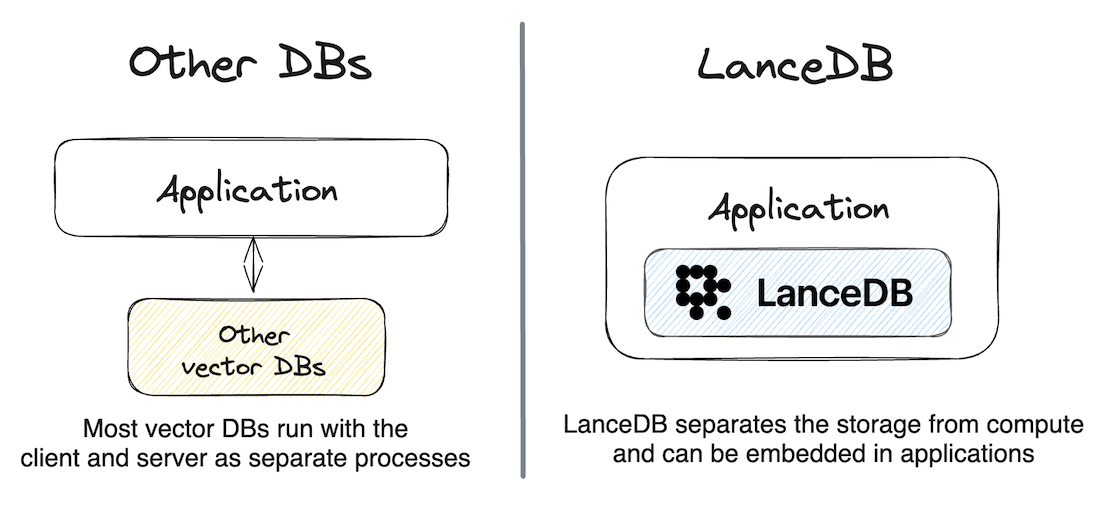
LanceDB can be run in a number of ways:
- Embedded within an existing backend (like your Django, Flask, Node.js or FastAPI application)
- Directly from a client application like a Jupyter notebook for analytical workloads
- Deployed as a remote serverless database
Installation
Bundling @lancedb/lancedb apps with Webpack
Since LanceDB contains a prebuilt Node binary, you must configure next.config.js to exclude it from webpack. This is required for both using Next.js and deploying a LanceDB app on Vercel.
Bundling vectordb apps with Webpack
Since LanceDB contains a prebuilt Node binary, you must configure next.config.js to exclude it from webpack. This is required for both using Next.js and deploying a LanceDB app on Vercel.
To use the lancedb create, you first need to install protobuf.
Please also make sure you're using the same version of Arrow as in the lancedb crate
Preview releases
Stable releases are created about every 2 weeks. For the latest features and bug fixes, you can install the preview release. These releases receive the same level of testing as stable releases, but are not guaranteed to be available for more than 6 months after they are released. Once your application is stable, we recommend switching to stable releases.
Connect to a database
#[tokio::main]
async fn main() -> Result<()> {
let uri = "data/sample-lancedb";
let db = connect(uri).execute().await?;
}
See examples/simple.rs for a full working example.
LanceDB will create the directory if it doesn't exist (including parent directories).
If you need a reminder of the uri, you can call db.uri().
Create a table
Create a table from initial data
If you have data to insert into the table at creation time, you can simultaneously create a table and insert the data into it. The schema of the data will be used as the schema of the table.
If the table already exists, LanceDB will raise an error by default.
If you want to overwrite the table, you can pass in mode="overwrite"
to the create_table method.
data = [
{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0},
]
tbl = db.create_table("my_table", data=data)
You can also pass in a pandas DataFrame directly:
const tbl = await db.createTable(
"myTable",
[
{ vector: [3.1, 4.1], item: "foo", price: 10.0 },
{ vector: [5.9, 26.5], item: "bar", price: 20.0 },
],
{ writeMode: lancedb.WriteMode.Overwrite },
);
If the table already exists, LanceDB will raise an error by default.
If you want to overwrite the table, you can pass in mode:"overwrite"
to the createTable function.
let initial_data = create_some_records()?;
let tbl = db
.create_table("my_table", initial_data)
.execute()
.await
.unwrap();
If the table already exists, LanceDB will raise an error by default. See the mode option for details on how to overwrite (or open) existing tables instead.
Providing
The Rust SDK currently expects data to be provided as an Arrow RecordBatchReader Support for additional formats (such as serde or polars) is on the roadmap.
Under the hood, LanceDB reads in the Apache Arrow data and persists it to disk using the Lance format.
Automatic embedding generation with Embedding API
When working with embedding models, it is recommended to use the LanceDB embedding API to automatically create vector representation of the data and queries in the background. See the quickstart example or the embedding API guide
Create an empty table
Sometimes you may not have the data to insert into the table at creation time.
In this case, you can create an empty table and specify the schema, so that you can add
data to the table at a later time (as long as it conforms to the schema). This is
similar to a CREATE TABLE statement in SQL.
You can define schema in Pydantic
LanceDB comes with Pydantic support, which allows you to define the schema of your data using Pydantic models. This makes it easy to work with LanceDB tables and data. Learn more about all supported types in tables guide.
Open an existing table
Once created, you can open a table as follows:
If you forget the name of your table, you can always get a listing of all table names:
Add data to a table
After a table has been created, you can always add more data to it as follows:
Search for nearest neighbors
Once you've embedded the query, you can find its nearest neighbors as follows:
This returns a pandas DataFrame with the results.
use futures::TryStreamExt;
table
.query()
.limit(2)
.nearest_to(&[1.0; 128])?
.execute()
.await?
.try_collect::<Vec<_>>()
.await
Query
Rust does not yet support automatic execution of embedding functions. You will need to calculate embeddings yourself. Support for this is on the roadmap and can be tracked at https://github.com/lancedb/lancedb/issues/994
Query vectors can be provided as Arrow arrays or a Vec/slice of Rust floats.
Support for additional formats (e.g. polars::series::Series) is on the roadmap.
By default, LanceDB runs a brute-force scan over dataset to find the K nearest neighbours (KNN). For tables with more than 50K vectors, creating an ANN index is recommended to speed up search performance. LanceDB allows you to create an ANN index on a table as follows:
Why do I need to create an index manually?
LanceDB does not automatically create the ANN index for two reasons. The first is that it's optimized for really fast retrievals via a disk-based index, and the second is that data and query workloads can be very diverse, so there's no one-size-fits-all index configuration. LanceDB provides many parameters to fine-tune index size, query latency and accuracy. See the section on ANN indexes for more details.
Delete rows from a table
Use the delete() method on tables to delete rows from a table. To choose
which rows to delete, provide a filter that matches on the metadata columns.
This can delete any number of rows that match the filter.
The deletion predicate is a SQL expression that supports the same expressions
as the where() clause (only_if() in Rust) on a search. They can be as
simple or complex as needed. To see what expressions are supported, see the
SQL filters section.
Read more: lancedb.table.Table.delete
Read more: lancedb.table.AsyncTable.delete
Read more: lancedb.Table.delete
Read more: vectordb.Table.delete
Read more: lancedb::Table::delete
Drop a table
Use the drop_table() method on the database to remove a table.
This permanently removes the table and is not recoverable, unlike deleting rows.
By default, if the table does not exist an exception is raised. To suppress this,
you can pass in ignore_missing=True.
Using the Embedding API
You can use the embedding API when working with embedding models. It automatically vectorizes the data at ingestion and query time and comes with built-in integrations with popular embedding models like Openai, Hugging Face, Sentence Transformers, CLIP and more.
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
db = lancedb.connect("/tmp/db")
func = get_registry().get("openai").create(name="text-embedding-ada-002")
class Words(LanceModel):
text: str = func.SourceField()
vector: Vector(func.ndims()) = func.VectorField()
table = db.create_table("words", schema=Words, mode="overwrite")
table.add([{"text": "hello world"}, {"text": "goodbye world"}])
query = "greetings"
actual = table.search(query).limit(1).to_pydantic(Words)[0]
print(actual.text)
Coming soon to the async API. https://github.com/lancedb/lancedb/issues/1938
import * as lancedb from "@lancedb/lancedb";
import "@lancedb/lancedb/embedding/openai";
import { LanceSchema, getRegistry, register } from "@lancedb/lancedb/embedding";
import { EmbeddingFunction } from "@lancedb/lancedb/embedding";
import { type Float, Float32, Utf8 } from "apache-arrow";
const db = await lancedb.connect(databaseDir);
const func = getRegistry()
.get("openai")
?.create({ model: "text-embedding-ada-002" }) as EmbeddingFunction;
const wordsSchema = LanceSchema({
text: func.sourceField(new Utf8()),
vector: func.vectorField(),
});
const tbl = await db.createEmptyTable("words", wordsSchema, {
mode: "overwrite",
});
await tbl.add([{ text: "hello world" }, { text: "goodbye world" }]);
const query = "greetings";
const actual = (await tbl.search(query).limit(1).toArray())[0];
use std::{iter::once, sync::Arc};
use arrow_array::{Float64Array, Int32Array, RecordBatch, RecordBatchIterator, StringArray};
use arrow_schema::{DataType, Field, Schema};
use futures::StreamExt;
use lancedb::{
arrow::IntoArrow,
connect,
embeddings::{openai::OpenAIEmbeddingFunction, EmbeddingDefinition, EmbeddingFunction},
query::{ExecutableQuery, QueryBase},
Result,
};
#[tokio::main]
async fn main() -> Result<()> {
let tempdir = tempfile::tempdir().unwrap();
let tempdir = tempdir.path().to_str().unwrap();
let api_key = std::env::var("OPENAI_API_KEY").expect("OPENAI_API_KEY is not set");
let embedding = Arc::new(OpenAIEmbeddingFunction::new_with_model(
api_key,
"text-embedding-3-large",
)?);
let db = connect(tempdir).execute().await?;
db.embedding_registry()
.register("openai", embedding.clone())?;
let table = db
.create_table("vectors", make_data())
.add_embedding(EmbeddingDefinition::new(
"text",
"openai",
Some("embeddings"),
))?
.execute()
.await?;
let query = Arc::new(StringArray::from_iter_values(once("something warm")));
let query_vector = embedding.compute_query_embeddings(query)?;
let mut results = table
.vector_search(query_vector)?
.limit(1)
.execute()
.await?;
let rb = results.next().await.unwrap()?;
let out = rb
.column_by_name("text")
.unwrap()
.as_any()
.downcast_ref::<StringArray>()
.unwrap();
let text = out.iter().next().unwrap().unwrap();
println!("Closest match: {}", text);
Ok(())
}
Learn about using the existing integrations and creating custom embedding functions in the embedding API guide.
What's next
This section covered the very basics of using LanceDB. If you're learning about vector databases for the first time, you may want to read the page on indexing to get familiar with the concepts.
If you've already worked with other vector databases, you may want to read the guides to learn how to work with LanceDB in more detail.
-
The
vectordbpackage is a legacy package that is deprecated in favor of@lancedb/lancedb. Thevectordbpackage will continue to receive bug fixes and security updates until September 2024. We recommend all new projects use@lancedb/lancedb. See the migration guide for more information. ↩↩↩↩↩↩↩↩↩↩↩↩↩↩