Vector search
Vector search is a technique used to search for similar items based on their vector representations, called embeddings. It is also known as similarity search, nearest neighbor search, or approximate nearest neighbor search.
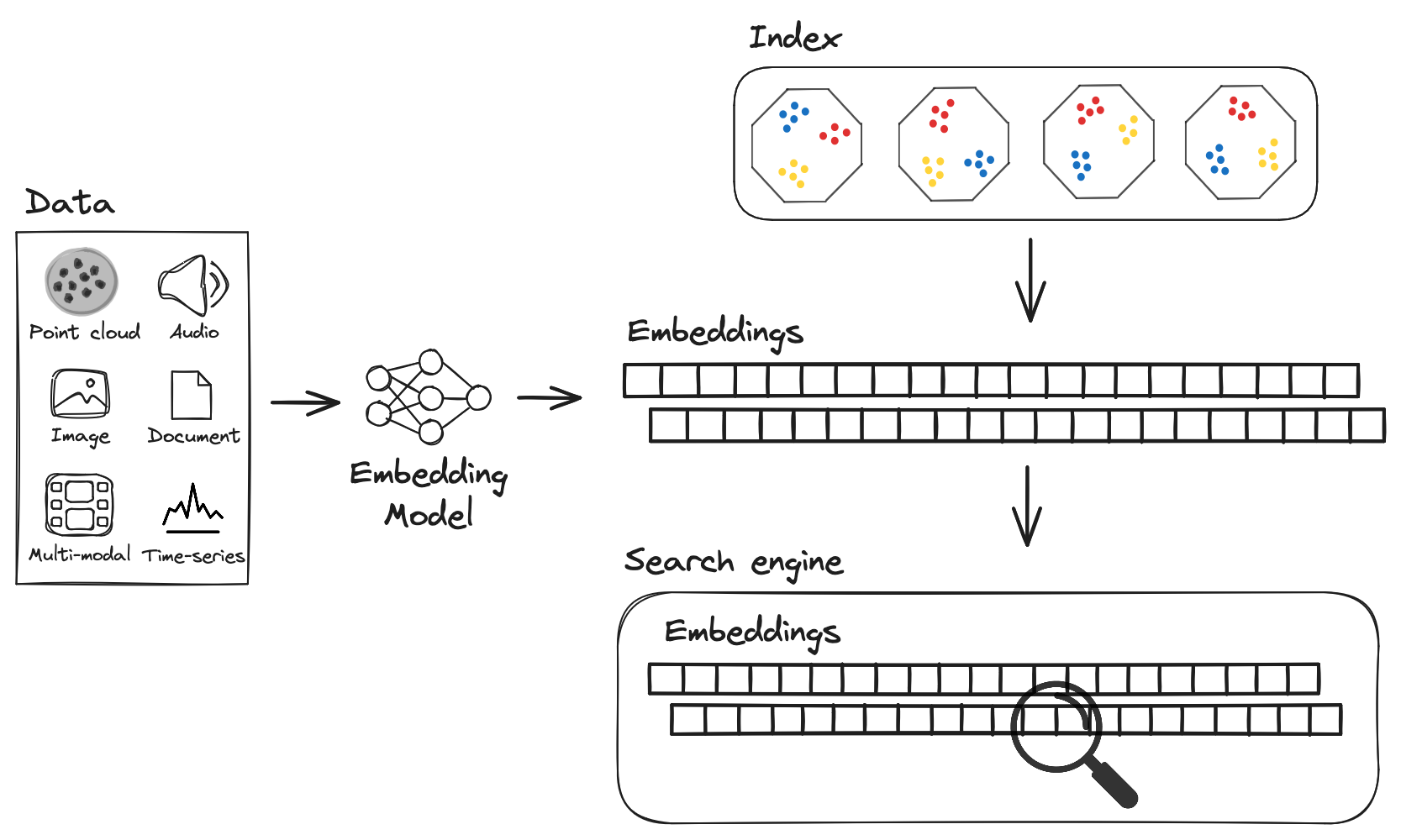
Raw data (e.g. text, images, audio, etc.) is converted into embeddings via an embedding model, which are then stored in a vector database like LanceDB. To perform similarity search at scale, an index is created on the stored embeddings, which can then used to perform fast lookups.
Embeddings
Modern machine learning models can be trained to convert raw data into embeddings, represented as arrays (or vectors) of floating point numbers of fixed dimensionality. What makes embeddings useful in practice is that the position of an embedding in vector space captures some of the semantics of the data, depending on the type of model and how it was trained. Points that are close to each other in vector space are considered similar (or appear in similar contexts), and points that are far away are considered dissimilar.
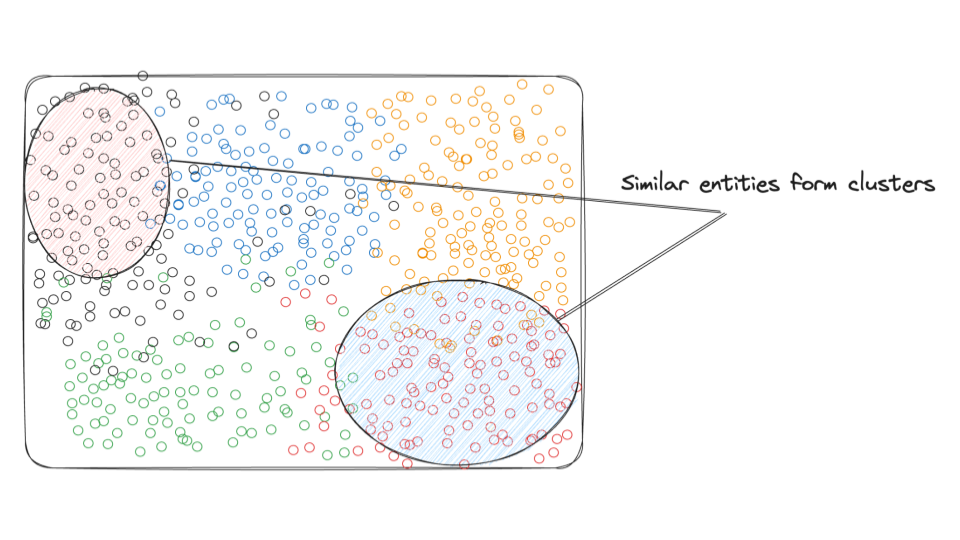
Large datasets of multi-modal data (text, audio, images, etc.) can be converted into embeddings with the appropriate model. Projecting the vectors' principal components in 2D space results in groups of vectors that represent similar concepts clustering together, as shown below.
Indexes
Embeddings for a given dataset are made searchable via an index. The index is constructed by using data structures that store the embeddings such that it's very efficient to perform scans and lookups on them. A key distinguishing feature of LanceDB is it uses a disk-based index: IVF-PQ, which is a variant of the Inverted File Index (IVF) that uses Product Quantization (PQ) to compress the embeddings.
See the IVF-PQ page for more details on how it works.
Brute force search
The simplest way to perform vector search is to perform a brute force search, without an index, where the distance between the query vector and all the vectors in the database are computed, with the top-k closest vectors returned. This is equivalent to a k-nearest neighbours (kNN) search in vector space.
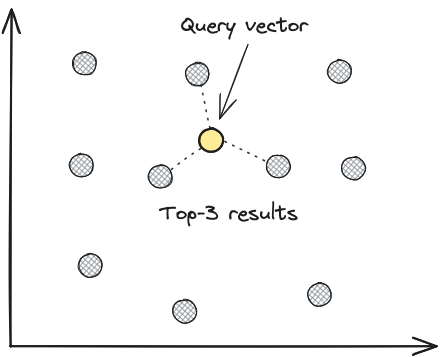
As you can imagine, the brute force approach is not scalable for datasets larger than a few hundred thousand vectors, as the latency of the search grows linearly with the size of the dataset. This is where approximate nearest neighbour (ANN) algorithms come in.
Approximate nearest neighbour (ANN) search
Instead of performing an exhaustive search on the entire database for each and every query, approximate nearest neighbour (ANN) algorithms use an index to narrow down the search space, which significantly reduces query latency. The trade-off is that the results are not guaranteed to be the true nearest neighbors of the query, but are usually "good enough" for most use cases.