Approximate Nearest Neighbor (ANN) Indexes
An ANN or a vector index is a data structure specifically designed to efficiently organize and search vector data based on their similarity via the chosen distance metric. By constructing a vector index, the search space is effectively narrowed down, avoiding the need for brute-force scanning of the entire vector space. A vector index is faster but less accurate than exhaustive search (kNN or flat search). LanceDB provides many parameters to fine-tune the index's size, the speed of queries, and the accuracy of results.
Disk-based Index
Lance provides an IVF_PQ disk-based index. It uses Inverted File Index (IVF) to first divide
the dataset into N partitions, and then applies Product Quantization to compress vectors in each partition.
See the indexing concepts guide for more information on how this works.
Creating an IVF_PQ Index
Lance supports IVF_PQ index type by default.
Creating indexes is done via the create_index method.
import lancedb
import numpy as np
uri = "data/sample-lancedb"
# Create 5,000 sample vectors
data = [
{"vector": row, "item": f"item {i}"}
for i, row in enumerate(np.random.random((5_000, 32)).astype("float32"))
]
db = lancedb.connect(uri)
# Add the vectors to a table
tbl = db.create_table("my_vectors", data=data)
# Create and train the index - you need to have enough data in the table
# for an effective training step
tbl.create_index(num_partitions=2, num_sub_vectors=4)
Creating indexes is done via the create_index method.
import lancedb
import numpy as np
from lancedb.index import IvfPq
uri = "data/sample-lancedb"
# Create 5,000 sample vectors
data = [
{"vector": row, "item": f"item {i}"}
for i, row in enumerate(np.random.random((5_000, 32)).astype("float32"))
]
async_db = await lancedb.connect_async(uri)
# Add the vectors to a table
async_tbl = await async_db.create_table("my_vectors_async", data=data)
# Create and train the index - you need to have enough data in the table
# for an effective training step
await async_tbl.create_index(
"vector", config=IvfPq(num_partitions=2, num_sub_vectors=4)
)
Creating indexes is done via the lancedb.Table.createIndex method.
import * as lancedb from "@lancedb/lancedb";
import type { VectorQuery } from "@lancedb/lancedb";
const db = await lancedb.connect(databaseDir);
const data = Array.from({ length: 5_000 }, (_, i) => ({
vector: Array(128).fill(i),
id: `${i}`,
content: "",
longId: `${i}`,
}));
const table = await db.createTable("my_vectors", data, {
mode: "overwrite",
});
await table.createIndex("vector", {
config: lancedb.Index.ivfPq({
numPartitions: 10,
numSubVectors: 16,
}),
});
Creating indexes is done via the lancedb.Table.createIndex method.
import * as vectordb from "vectordb";
const db = await vectordb.connect("data/sample-lancedb");
let data = [];
for (let i = 0; i < 10_000; i++) {
data.push({
vector: Array(1536).fill(i),
id: `${i}`,
content: "",
longId: `${i}`,
});
}
const table = await db.createTable("my_vectors", data);
await table.createIndex({
type: "ivf_pq",
column: "vector",
num_partitions: 16,
num_sub_vectors: 48,
});
// For this example, `table` is a lancedb::Table with a column named
// "vector" that is a vector column with dimension 128.
// By default, if the column "vector" appears to be a vector column,
// then an IVF_PQ index with reasonable defaults is created.
table
.create_index(&["vector"], Index::Auto)
.execute()
.await?;
// For advanced cases, it is also possible to specifically request an
// IVF_PQ index and provide custom parameters.
table
.create_index(
&["vector"],
Index::IvfPq(
// Here we specify advanced indexing parameters. In this case
// we are creating an index that my have better recall than the
// default but is also larger and slower.
IvfPqIndexBuilder::default()
// This overrides the default distance type of l2
.distance_type(DistanceType::Cosine)
// With 1000 rows this have been ~31 by default
.num_partitions(50)
// With dimension 128 this would have been 8 by default
.num_sub_vectors(16),
),
)
.execute()
.await?;
IVF_PQ index parameters are more fully defined in the crate docs.
The following IVF_PQ paramters can be specified:
- distance_type: The distance metric to use. By default it uses euclidean distance "
l2". We also support "cosine" and "dot" distance as well. - num_partitions: The number of partitions in the index. The default is the square root of the number of rows.
Note
In the synchronous python SDK and node's vectordb the default is 256. This default has
changed in the asynchronous python SDK and node's lancedb.
- num_sub_vectors: The number of sub-vectors (M) that will be created during Product Quantization (PQ).
For D dimensional vector, it will be divided into
Msubvectors with dimensionD/M, each of which is replaced by a single PQ code. The default is the dimension of the vector divided by 16. - num_bits: The number of bits used to encode each sub-vector. Only 4 and 8 are supported. The higher the number of bits, the higher the accuracy of the index, also the slower search. The default is 8.
Note
In the synchronous python SDK and node's vectordb the default is currently 96. This default has
changed in the asynchronous python SDK and node's lancedb.
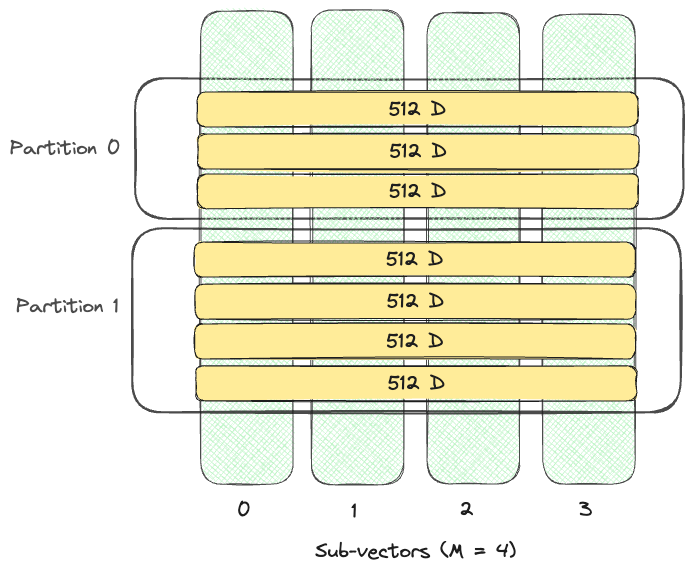
num_partitions=2, num_sub_vectors=4Use GPU to build vector index
Lance Python SDK has experimental GPU support for creating IVF index. Using GPU for index creation requires PyTorch>2.0 being installed.
You can specify the GPU device to train IVF partitions via
- accelerator: Specify to
cudaormps(on Apple Silicon) to enable GPU training.
Note
GPU based indexing is not yet supported with our asynchronous client.
Troubleshooting:
If you see AssertionError: Torch not compiled with CUDA enabled, you need to install
PyTorch with CUDA support.
Querying an ANN Index
Querying vector indexes is done via the search function.
There are a couple of parameters that can be used to fine-tune the search:
- limit (default: 10): The amount of results that will be returned
-
nprobes (default: 20): The number of probes used. A higher number makes search more accurate but also slower.
Most of the time, setting nprobes to cover 5-15% of the dataset should achieve high recall with low latency.- For example, For a dataset of 1 million vectors divided into 256 partitions,
nprobesshould be set to ~20-40. This value can be adjusted to achieve the optimal balance between search latency and search quality.
- For example, For a dataset of 1 million vectors divided into 256 partitions,
-
refine_factor (default: None): Refine the results by reading extra elements and re-ranking them in memory.
A higher number makes search more accurate but also slower. If you find the recall is less than ideal, try refine_factor=10 to start.- For example, For a dataset of 1 million vectors divided into 256 partitions, setting the
refine_factorto 200 will initially retrieve the top 4,000 candidates (top k * refine_factor) from all searched partitions. These candidates are then reranked to determine the final top 20 results.
- For example, For a dataset of 1 million vectors divided into 256 partitions, setting the
Note
Both nprobes and refine_factor are only applicable if an ANN index is present. If specified on a table without an ANN index, those parameters are ignored.
let query_vector = [1.0; 128];
// By default the index will find the 10 closest results using default
// search parameters that give a reasonable tradeoff between accuracy
// and search latency
let mut results = table
.vector_search(&query_vector)?
// Note: you should always set the distance_type to match the value used
// to train the index
.distance_type(DistanceType::Cosine)
.execute()
.await?;
while let Some(batch) = results.try_next().await? {
println!("{:?}", batch);
}
// We can also provide custom search parameters. Here we perform a
// slower but more accurate search
let mut results = table
.vector_search(&query_vector)?
.distance_type(DistanceType::Cosine)
// Override the default of 10 to get more rows
.limit(15)
// Override the default of 20 to search more partitions
.nprobes(30)
// Override the default of None to apply a refine step
.refine_factor(1)
.execute()
.await?;
while let Some(batch) = results.try_next().await? {
println!("{:?}", batch);
}
Ok(())
Vector search options are more fully defined in the crate docs.
The search will return the data requested in addition to the distance of each item.
Filtering (where clause)
You can further filter the elements returned by a search using a where clause.
Projections (select clause)
You can select the columns returned by the query using a select clause.
FAQ
Why do I need to manually create an index?
Currently, LanceDB does not automatically create the ANN index. LanceDB is well-optimized for kNN (exhaustive search) via a disk-based index. For many use-cases, datasets of the order of ~100K vectors don't require index creation. If you can live with up to 100ms latency, skipping index creation is a simpler workflow while guaranteeing 100% recall.
When is it necessary to create an ANN vector index?
LanceDB comes out-of-the-box with highly optimized SIMD code for computing vector similarity.
In our benchmarks, computing distances for 100K pairs of 1K dimension vectors takes less than 20ms.
We observe that for small datasets (~100K rows) or for applications that can accept 100ms latency,
vector indices are usually not necessary.
For large-scale or higher dimension vectors, it can beneficial to create vector index for performance.
How big is my index, and how many memory will it take?
In LanceDB, all vector indices are disk-based, meaning that when responding to a vector query, only the relevant pages from the index file are loaded from disk and cached in memory. Additionally, each sub-vector is usually encoded into 1 byte PQ code.
For example, with a 1024-dimension dataset, if we choose num_sub_vectors=64, each sub-vector has 1024 / 64 = 16 float32 numbers.
Product quantization can lead to approximately 16 * sizeof(float32) / 1 = 64 times of space reduction.
How to choose num_partitions and num_sub_vectors for IVF_PQ index?
num_partitions is used to decide how many partitions the first level IVF index uses.
Higher number of partitions could lead to more efficient I/O during queries and better accuracy, but it takes much more time to train.
On SIFT-1M dataset, our benchmark shows that keeping each partition 4K-8K rows lead to a good latency / recall.
num_sub_vectors specifies how many Product Quantization (PQ) short codes to generate on each vector. The number should be a factor of the vector dimension. Because
PQ is a lossy compression of the original vector, a higher num_sub_vectors usually results in
less space distortion, and thus yields better accuracy. However, a higher num_sub_vectors also causes heavier I/O and more PQ computation, and thus, higher latency. dimension / num_sub_vectors should be a multiple of 8 for optimum SIMD efficiency.
Note
if num_sub_vectors is set to be greater than the vector dimension, you will see errors like attempt to divide by zero
How to choose m and ef_construction for IVF_HNSW_* index?
m determines the number of connections a new node establishes with its closest neighbors upon entering the graph. Typically, m falls within the range of 5 to 48. Lower m values are suitable for low-dimensional data or scenarios where recall is less critical. Conversely, higher m values are beneficial for high-dimensional data or when high recall is required. In essence, a larger m results in a denser graph with increased connectivity, but at the expense of higher memory consumption.
ef_construction balances build speed and accuracy. Higher values increase accuracy but slow down the build process. A typical range is 150 to 300. For good search results, a minimum value of 100 is recommended. In most cases, setting this value above 500 offers no additional benefit. Ensure that ef_construction is always set to a value equal to or greater than ef in the search phase